
АНАЛИЗ ВОЗМОЖНОСТЕЙ ПРИМЕНЕНИЯ ГОЛОСОВОЙ ИДЕНТИФИКАЦИИ В СИСТЕМАХ РАЗГРАНИЧЕНИЯ ДОСТУПА К ИНФОРМАЦИИ
Aннотация
При учете проблемы повышения надежности систем разграничения доступа предложен новый метод и алгоритм идентификации на основе элементарных речевых единиц. На их основе представлены программная реализация и результаты экспериментальных исследований разработанной информационной системы в задаче идентификации пользователей по голосу при различных условиях и возможность применения в системах разграничения доступа.
Ключевые слова: идентификация по голосу, системы разграничения доступа, защита информации от несанкционированного доступа, фонетический анализ речи, элементарные речевые единицы
Введение
В последние годы для идентификации личности человека наиболее перспективным считается применение биометрических технологий [1, 2, 3, 4], особенно в системах разграничения доступа, при проведении финансовых операций, при запросах информации ограниченного доступа по телефону, при управлении различными устройствами, в криминалистике и т.д. Применение биометрических технологий обладает рядом существенных преимуществ перед традиционными средствами идентификации, например надёжность идентификации и удобство использования [4].
Наиболее широкое применение в биометрической идентификации получили следующие параметры человека: особенности геометрии лица, отпечатки пальца, геометрия ладони рук, сетчатка и радужная оболочка глаза, голосовые характеристики, особенности подписи и клавиатурный подчерк. В некоторых случаях применение биометрических характеристик человека осложнено. Геометрии лица свойственна низкая уникальность, для анализа сетчатки и радужной оболочки глаза требуется дорогостоящее оборудование. Параметрам клавиатурного подчерка и подписи свойственна низкая стабильность и зависимость от эмоционального состояния человека. При применении сканеров отпечатков пальцев и геометрии ладони рук возможны вопросы чистоты контактных площадок и соблюдения санитарных норм.
Свести к минимуму недостатки указанных выше методов биометрической идентификации пользователей позволит разработка нового бесконтактного метода с использованием биометрических характеристик.
К подобному методу биометрической идентификации пользователей информационных систем относится идентификация по голосу, позволяющая получать и передавать в удостоверяющий центр биометрические данные без применения специализированных и дорогостоящих съемников биометрической информации: достаточно иметь телефон или микрофон, подключенный к компьютеру.
На данный момент распространенным методом при решении задач анализа и идентификации голоса является байесовский подход [6]. В основе принципа данного метода речевые единицы (РЕ) представляются гауссовой моделью сигналов и набором классов. Недостатками данного подхода является невысокая точность и надежность. Для сведения к мнимому указанных недостатков профессором Савченко В.В. была создана информационная теория восприятия речи (ИТВР) [5], фундаментом которой служит критерий минимума информационных рассогласований (МИР) [6] и кластерная модель речевых единиц. ИТВР можно считать одним из наиболее прогрессивным направлением развития акустической теории звука [7].
На данный момент существует множество зарубежных (Agnitio, Nuance, Voice Security Systems) и отечественных (Речевые технологии, Центр речевых технологий) компаний, разрабатывающих системы голосовой биометрии [2, 3, 4]. В большинстве разработанных систем вероятность ошибки идентификации составляет 1 - 3%, но данные разработки обладают рядом недостатков.
В большинстве существующих систем идентификации по голосу отсутствует настройка алгоритмов под изменяющиеся условия применения (уровень шума, фонемы речи конкретного человека, ошибки идентификации и т.д.), для осуществления процедуры идентификации используется спектральный анализ входного звукового сигнала и эталонного сигнала, записанного в базу, тем самым существует привязка к эталонным фразам.
Поэтому актуальной становится задача создания нового метода и алгоритма идентификации голосового сообщения по индивидуальным характеристикам голоса без представленных недостатков, позволяющая производить текстонезависимую идентификацию в условиях малой обучающей выборки, а также создать систему идентификации дикторов по голосу, реализующую данную модель и позволяющей её тестировать.
Объекты и методы исследования
Новизна метода идентификации заключается в кластеризации голосовых эталонов диктора, при этом звуковой сигнал сегментируется на элементарные речевые единицы. Далее все сегменты последовательно сравниваются с порогом по длительности и спектру, и в случае недостаточной длины и несоответствия спектра, текущий сегмент отбрасывается, переходя к следующему сегменту. После отбора таким образом элементарных речевых единиц, они проверяются на соответствие уже существующим в базе данных фреймам путем расчета вероятности информационного рассогласования между самим сегментом и эталонной реализацией фрейма. Элементарные речевые единицы относятся к тому фрейму, где вероятность информационного рассогласования минимальна, при условии, что она не превышает некоторого априорно установленного порога, после этого формируется кластер эталонов диктора. В противном случае формируем новый фрейм, который будет содержать единственный элемент – эту элементарную речевую единицу.
Схема метода кластеризации голосовых эталонов на основе элементарных речевых единиц отображена на рисунке 1.
Разработанный алгоритм идентификации использует в своей основе метод накопления полезной информации по результатам сравнения двух фонетических баз данных: тестируемой и эталонной (точнее, одной из эталонных) на множестве их элементарных речевых единиц. Указанный принцип широко применяется во многих системах при обработке информации на фоне помех, в частности, в радиолокационных системах. Основываясь на данном принципе был разработан новый метод статистического анализа фонем диктора для решения задачи идентификации по голосу.
В радиолокационных системах совокупность участков одной и той же дальности в различных азимутальных позициях зоны обзора составляет кольцо дальности, в котором и происходит накопление импульсных сигналов, что соответствует логике разработанной кластерной модели речевых единиц, где присутствует информационный центр множества реализаций фонем диктора и представлено информативное описание свойств речевой единицы.
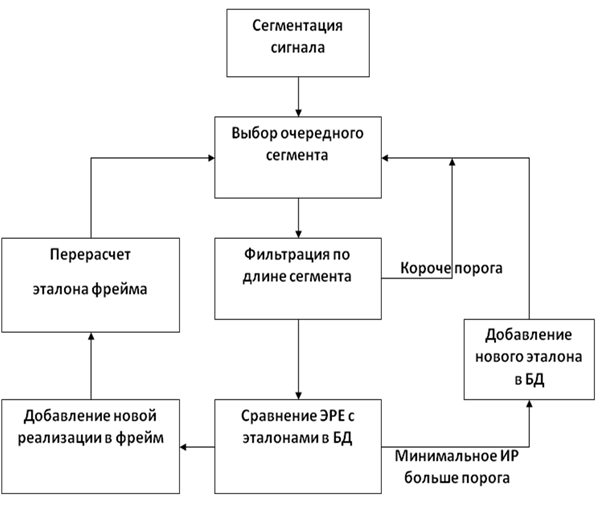
Рис. 1. Схема метода кластеризации голосовых эталонов на основе элементарных речевых единиц
Fig. 1. Diagram of a method of clustering voice standards-based elementary speech units
Следовательно, оптимальное правило обнаружения сигнала по выборке его N дискретных значений заключается в сравнении числа единиц в выборке с пороговым числом k0. Если k>k0, то принимается решение о приеме сигнала, в противном случае об его отсутствии, что по логике соответствует принятию решения о принадлежности определяемой фонемы конкретному диктору или о её отвержении.
На основе совместного использования метода кластеризации элементарных речевых единиц и метода накопления информации был разработан новый адаптированный алгоритм идентификации фонем диктора.
Блок-схема алгоритма идентификации, реализуемого в среде программирования Matlab, отображена на рисунке 2.
В данной схеме names – массив фреймов в базе данных, tabulate(names) – алгоритм нахождения наиболее часто встречающегося фрейма, ii – переменный индекс фрейма диктора, namespeaker – обозначение (ФИО) диктора.
Таким образом разработан и реализован новый усовершенствованный алгоритм идентификации по голосу, основанный на совместном использовании метода кластеризации элементарных речевых единиц и метода накопления информации.

Рис. 2. Блок-схема алгоритма идентификации диктора по голосу
Fig. 2. Block diagram of a voice-based speaker identification
На рисунке 3 изображена блок-схема разработанной «информационной системы идентификации дикторов по голосу».
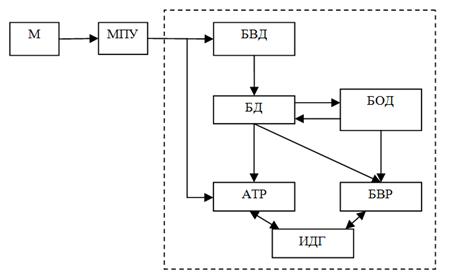
Рис. 3. Блок-схема «информационной системы идентификации дикторов по голосу»
Fig. 3. Block diagram of the «information system of a voice-based speaker identification»
Здесь М–микрофон, БВР – блок вывода результатов, БД – база данных, БОД – блок обработки данных, МПУ – микрофонный предусилитель, БВД – блок ввода данных, АТР – подсистема автоматического транскрибирования речевых сигналов, ИДГ – подсистема идентификации дикторов по голосу.
Результаты и их обсуждение
Для реализации предложенного алгоритма идентификации был разработан лабораторный образец «ИС ИДГ» [14]. Данная система представляет собой программный комплекс с расширенным функционалом для идентификации дикторов. Варианты применения данной информационной системы можно привести из самых различных областей. Это может быть, например, задача идентификации диктора по голосу, как для отдельного диктора, так и для группы дикторов, в зависимости от возраста, пола, национальности, эмоционального состояния. В качестве прикладной задачи можно привести удаленную идентификацию диктора при передаче речевого сигнала по каналам связи при низком качестве речи и высоком уровне помех.
При разработке «ИС ИДГ» были учтены требования ГОСТ Р 52633-2006 «Защита информации. Техника защиты информации. Требования к средствам высоконадежной биометрической идентификации» и ГОСТ Р ИСО/МЭК 19785-1-2008 «Автоматическая идентификация. Идентификация биометрическая. Единая структура форматов обмена биометрическими данными». Для работы необходим персональный компьютер с процессором класса не ниже 2000 МГц и 1Гб оперативной памяти, операционная система Windows, среда программирования Matlab, а также звуковая карта с частотой дискретизации 8 КГц и возможностью записи звуковых файлов в формате WAV.
Интерфейс «ИС ИДГ» состоит из главной формы, в которой отображаются дикторы, внесенные в базу данных. В данном меню возможен выбор режим работы, загрузка звукового файла, сохранение и последующее отображения данных. Общий вид интерфейса показан на рисунке 4.
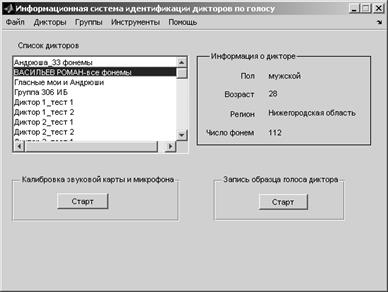
Рис. 4. Интерфейс «информационной системы идентификации дикторов по голосу»
Fig. 4. Interface of the «information system of a voice-based speaker identification»
В представленном окне информационной системы отображаются дикторы, внесенные в базу данных. При выборе диктора из списка отображается краткая информация данном человеке.
На рисунке 5 изображен главный раздел информационной системы, в котором осуществляется последовательное сегментирование звукового сигнала, выделение фонем диктора и его последующая идентификация.

Рис. 5. Интерфейс раздела «Идентификация»
Fig. 5. Interface section «Identification»
Для ввода звукового файла исследуемого диктора выбирается меню "Сигнал"->"Загрузить". Загруженный звуковой файл неизвестного нам диктора отображается в виде звуковой дорожки. Далее звуковой файл разбивается на определенное количество фреймов, для этого необходимо в меню «Сегментирование» выбрать «Старт».
После того как звуковой файл разбит на фреймы, нам необходимо установить принадлежность записанного в данном файле голоса тому или иному диктору. Для этого в меню «Идентификация» нажимаем кнопку «Старт», при этом происходит подсчет всех фреймов и по наиболее часто повторяющимся (не менее 60%), названным в соответствии с именем диктора, принимается решение о принадлежности данного голоса конкретному диктору. Фреймы заведомо неизвестного диктора сравниваются с фреймами различных дикторов, занесенных в фонетическую базу данных.
Тестирование «ИС ИДГ» проводилось в соответствии с правилами тестирования систем идентификации, установленными в стандарте ИСО/МЭК 19795-1-2007 «Автоматическая идентификация. Идентификация биометрическая. Эксплуатационные испытания и протоколы испытаний в биометрии. Часть 1. Принципы и структура». В соответствии с данным стандартом необходимо проводить испытания в зависимости от возрастных, гендерных, физиологических, эмоциональных состояний испытуемой группы.
Программа экспериментальных испытаний информационной системы идентификации дикторов по голосу, проведенных в соответствии с описанной выше схемой, приведена в таблице 1 [8-13].
Таблица 1
Программа экспериментальных испытаний информационной системы идентификации дикторов по голосу
Table 1
The program of experimental tests of the information system of a voice-based speaker identification
№ | Название эксперимента | Программа и методики исследований |
№1 | Выявление различия фонем дикторов для процедуры идентификации | Записаны отдельные фонемы 10 дикторов, произведен анализ и сегментация фонем, произведена идентификация фонем конкретного диктора из общей базы фонем |
№2 | Выявление различия в произношении дикторов для проведения процедуры идентификации по отдельным фразам | Записаны слова с ярко выраженными фонемами 10 дикторов, произведен анализ и сегментация слов, произведена идентификация конкретного диктора из общей базы записанных контрольных фраз |
№3 | Проведения текстонезависимой идентификации дикторов по непрерывной речи | Записаны 10 дикторов в режиме непрерывного монолога, создана общая база речи дикторов, произведена идентификация диктора по записанной в режиме онлайн слитной русской речи (предложения, записанные в базу, отличаются от произносимых онлайн) |
№4 | Определение национальности диктора при проведении процедуры идентификации | Записаны 10 дикторов разной национальности, при записи дикторы говорили в режиме монолога на своем родном языке (немецкий, азербайджанский, английский, арабский, испанский, итальянский, китайский, французский, чешский, русский), создана база дикторов, произведена процедура идентификации, выявлены отличия фонем дикторов разных национальностей |
№5 | Определение влияния физического и эмоционального состояния дикторов на процесс идентификации | Записаны 4 диктора в режиме монолога, 1-я запись проведена в устойчивом состоянии, 2-я запись проводилась после физ. нагрузки и в состоянии стресса, создана база фонем дикторов, при идентификации выявлено отличие фонем дикторов в зависимости от эмоционального состояния |
№6 | Исследование вероятности правильной идентификации при использовании технологий клонирования и пародирования речи (voice changing) для модификации «подделки» голоса диктора | Записано 5 фонограмм известных дикторов в режиме монолога, 1-я запись проведена на обычный микрофон без применения сторонних программ, 2-я запись проводилась с привлечением «пародистов» голоса и применением специализированных программ клонирования голоса Morphvox и Voice changer, произведена попытка модификации голоса первого диктора для «подделки» голоса второго диктора, создана база фонем дикторов, при идентификации выявлено отличие фонем дикторов в зависимости от «живого» и «подделанного» голоса , процент распознанных фонем позволяет определить реального диктора от его клона |
Таким образом, стандарт ИСО/МЭК 19795-1 был адаптирован под испытания систем идентификации человека по речевому сигналу.
Так же по результатам эксперимента сделан вывод, что при увеличении числа идентифицируемых дикторов качество идентификации не снижается, в связи с чем в разработанной информационной системе нет явного ограничения на количество пользователей.
Представленные выше эксперименты проведены в разработанной «ИС ИДГ» и в аналогичных программно-аппаратных и программных комплексах идентификации по голосу российских производителей, среди которых система «VoiceKey» - ООО «Центр речевых технологий», система «ИКАР Лаб» - ООО «Центр речевых технологий», GritTec Speaker-ID – ООО“ГритТек”.
В таблице 2 представлено сравнение показателей программно-аппаратных комплексов идентификации по голосу российских производителей.
Таблица 2
Сравнение показателей программно-аппаратных комплексов идентификации по голосу российских производителей
Table 2
Comparison of software and hardware systems of voice-based identification produced by Russian manufacturers
Система идентификации | «ИКАР Лаб» | «ИС ИДГ» | «Voice Key» | «GTS-ID» |
Параметры проверки системы | ||||
EER (Equal Error Rate) - вероятность ошибок биометрической системы доступа, при котором FAR и FRR равны | 1.1-2.6% | 1.1 - 2.86% | 2–3.3% | 4.1% |
Отказ в регистрации | 1% | 2% | 4% | ~0% |
FAR (False Acceptance Rate) – вероятность ложного принятия. Вероятность принятия «чужого» диктора за «своего» (ошибка второго рода) | 1,2% | 0.5% | 2.5% | 4% |
FRR (False Rejection Rate) – вероятность ложного отклонения. Вероятность отклонения «своего» диктора, приняв его за «чужого» (ошибка первого рода) | 0.001% | 0.25% | 0.1% | 0.4% |
Стоимость системы | Очень высокая | Низкая | Высокая | Высокая |
Проведя анализ полученных результатов, можно сделать вывод, что разработанная в рамках диссертационных исследований «ИС ИДГ» имеет ряд преимуществ над системами аналогами, показав низкую вероятность ошибок при равных значениях FAR и FRR, небольшой процент ошибок при регистрации, низкую вероятность ложного принятия (FAR), но при этом «ИС ИДГ» уступает аналогам по показателям вероятности ложного отклонения (FRR). Алгоритмы идентификации «ИС ИДГ» возможно внедрить в существующие системы для разграничения прав доступа к корпоративным ресурсам в сети и в телефонном канале в режиме реального времени.
«ИС ИДГ» может выступать самостоятельно или дополнять имеющиеся системы разграничения доступа. Использование сервиса позволяет исключить случаи несанкционированного доступа к ресурсам, возникающие в случае утери, кражи, передачи обычного символьного пароля (вводимого с клавиатуры компьютера), HID (Proximity) RFID карты, hasp-ключа и т.д., в отличие от голоса, который всегда остается у пользователя системы.
Алгоритм разграничения доступа предусматривает наличие нескольких этапов работы информационной системы. На 1-м этапе происходит запись эталонного голоса диктора, а на 2-м - сравнение произнесенного голоса с эталоном. В стандартных алгоритмах идентификации существует следующий недостаток: нарушитель может записать на диктофон эталонное голосовое сообщение, а далее получить доступ воспроизведя данную запись. Для исключения данного недостатка предлагается следующий алгоритм работы системы разграничения доступа, рисунок 6.

Рис. 6. Алгоритм работы системы разграничения доступа по голосу
Fig. 6. Algorithm of the system of voice verification access control
На 1-м этапе записываются не связанные между собой короткие голосовые сообщения в виде отдельных слов (существительное, глагол, прилагательное, например, «мама мыла раму»). В алгоритме под цифрой 1 обозначен микрофон, 2- канал связи, 3 - аналого-цифровой преобразователь, 4- запоминающее устройство. На 2-м этапе информационная система выбирает несколько записанных диктором звуковых сообщений и предоставляет диктору возможность в выбранном порядке произнести данные слова с указанием текста в окне системы. Диктор произносит данные слова для последующего анализа в устройстве анализа данных – 5. Далее устройство идентификации – 6, выполняет процедуру анализа и подсчета повторяющихся фонем диктора, выполняет проверку содержания распознанных фонем в соответствии с произнесенным словом. При наибольшем соответствии фонем определенному диктору (не менее 60%) и совпадении произнесенных слов со словами в окне системы, принимается решение о предоставлении доступа пользователю.
Далее оценим эффективность предложенной схемы идентификации. Пусть при записи фонем используется N фраз. При идентификации голос диктора формируется из n эталонов. Тогда количество фонем диктора К будет равно:
 (1)
(1)
Если нарушитель записал произношение диктора, то при попытке взлома, вероятность Р того, что записанное им сообщение совпадёт с запрашиваемым системой идентификации будет равна:
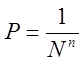 (2)
(2)
Ниже приведена таблица 3 вероятностей Р, рассчитанных в соответствие с формулой (2) для значений N и n. По горизонтали расположены значения N, а по вертикали - n, на пересечении столбца и строки - соответствующая им вероятность Р.
Таблица 3
Вероятности Р, рассчитанные для некоторых значений N и n
Table 3
The probabilities of P calculated for certain values of N and n
n\N | 5 | 10 | 15 | 20 | 25 |
1 | 0,2 | 0,1 | 0,07 | 0,05 | 0,04 |
2 | 0,04 | 0,01 | 0,004 | 0,0025 | 0,0016 |
3 | 0,008 | 0,001 | 0,0003 | 0,000125 | 0,000064 |
4 | 0,0016 | 0,0001 | 0,0000198 | 0,00000625 | 0,00000256 |
5 | 0,00032 | 0,00001 | 0,0000013169 | 0,0000003125 | 0,0000001024 |
Как видно из таблицы, вероятность Р мала, поэтому вероятность взлома системы, даже, если нарушителю удалось подслушать и записать произношение фразы, также мала.
Заключение
Новизна и инновационность разработанного метода идентификации по голосу заключается в независимости от языка, национальности, возраста, пола, эмоционального состояния и здоровья диктора. Для идентификации требуется парольная фраза длиной всего 3-5 секунд, что позволяет существенно экономить время при прохождении этой процедуры и полностью ее автоматизировать. Динамически меняющаяся парольная фраза, которую предлагают произнести пользователю (например, определенную последовательность цифр) позволяет надежность систем разграничения доступа и защиты информации.
Полученные результаты применимы как в системах защиты информации от несанкционированного доступа [15], использующие параметры голоса для идентификации пользователей, так и в системах разграничения доступа в помещения с голосовой идентификацией. Разработанный алгоритм идентификации так же можно применять в системах криминалистической (фонетической) экспертизы, использующих в качестве доказательной базы голос подозреваемого.










Список литературы
1. Аграновский A.B., Леднов Д.А., Репалов С.А. Метод текстонезависимой идентификации диктора на основе индивидуальности произношения гласных звуков // Акустика и прикладная лингвистика: Ежегодник РАО. Вып. 3. - М.: 2002. С. 103-115.
2. Центр речевых технологий [Электронный ресурс]: официальный сайт компании «Центр речевых технологий». URL: http://www.speechpro.ru (дата обращения: 23.10.2015).
3. Agnitio — Voice Biometrics [Электронный ресурс]: официальный сайт компании «Agnitio». URL: http://www.agnitio.es (дата обращения: 29.10.2015).
4. Nuance — The Leading Supplier of Speech Recognition, Imaging, PDF and OCR Solutions [Электронный ресурс]: официальный сайт компании «Nuance». URL: http://www.nuance.com (дата обращения: 21.10.2015).
5. Савченко В.В. Информационная теория восприятия речи // Известия вузов. Радиоэлектроника. 2007. Вып.6. С. 10-14.
6. Кульбак С. Теория информации и статистика. М.: Наука, 1967. 408 с.
7. Савченко В.В., Акатьев Д.Ю. Автотестирование качества произношения речи по принципу минимального информационного рассогласования // Сборник научных трудов «Современные тенденции компьютеризации процесса изучения иностранных языков». Луганск: Восточно-украинский национальный университет. 2005. Вып.3. С.205-206.
8. Васильев Р.А. Исследование особенностей фонетического строя речи и текстонезависимая идентификация дикторов по непрерывной речи // Информационная безопасность регионов. 2012. № 2 (11). С. 57-63.
9. Vasilyev R. A. Research of a phonetic system of the speech and identification of announcers on a voice//Questions of information security. 2013. No. 1 (100). Pp. 43-51.
10. Васильев Р.А. Исследование особенностей фонетического строя речи и определение национальности диктора при проведении процедуры идентификации по голосу // Информация и безопасность. 2012. Т. 15. № 4. С. 487-494.
11. Васильев Р.А. Исследование особенностей идентификации дикторов по голосу при использовании технологий клонирования и пародирования речи для модификации голоса диктора // Известия Тульского государственного университета. Технические науки. 2013. № 3. С. 246-252.
12. Васильев Р.А. Исследование особенностей идентификации дикторов по голосу при различиях в произношении дикторов// Безопасность информационных технологий. 2013. № 1. С. 85-86.
13. Савченко В.В., Васильев Р.А. Анализ эмоционального состояния диктора по голосу на основе фонетического детектора лжи // Научные ведомости Белгородского государственного университета. 2014. Вып. № 21 (192) 32/1. С 186-195.
14. Васильев Р.А. 2015. Программа идентификации дикторов по голосу. Программа для ЭВМ. Свидетельство РФ №2015663306.
15. Николаев Д.Б., Мартынов А.П., Фомченко В.Н., Технические средства и методы обеспечения безопасности информации // ФГУП "Российский федеральный ядерный центр - Всероссийский науч.-исслед. ин-т экспериментальной физики". - Саров: РФЯЦ-ВНИИЭФ, 2015. - 393 с.